![[AWS] 단계별 시나리오를 통해 알아보는 EC2 Auto Scaling](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnQ76o%2Fbtq9iAlTsf4%2FCs9WhZFkIS8gmckFi7XNs1%2Fimg.png)
AutoScaling이란?
클라우드 컴퓨팅의 대표적인 장점 중 하나는 유연성이다.
유연성이라는 단어는 상당히 추상적이며 많은 의미를 내포하고 있지만 그 중 핵심은 빠르고 쉽게 서비스를 확장하거나 축소하는 것을 의미할 것이다.
Auto Scaling은 이 유연성을 돋보이게 하는 핵심 기술로 CPU, Memory, Disk, Network 등의 시스템 Metric값이나 Application을 모니터링하고 size를 자동으로 조절하는 기술이다.
Auto Scaling을 통해 얻을 수 있는 이득은 크게 2가지로 정의할 수 있다.
- 예상치 못한 서비스 부하에 효과적으로 대응할 수 있다.
- 최대한 저렴한 비용으로 안정적이고 예측 가능한 성능을 유지할 수 있다.
AWS Auto Scaling Resource
AWS에서는 인스턴스, DB 등 다양한 서비스에서 Auto Scaling을 지원한다.
이 중 오늘 포스팅에서는 EC2 Auto Scaling에 대해 알아보자.

EC2 Auto Scaling 실습 시나리오
1. S3 버킷 및 IAM 생성
우선 ec2에 연결할 S3 버킷을 생성한다.
굳이 필요없는 작업이긴 하지만 조금이나마 의미있는 시나리오를 구성하기 위해 준비하였다.

web 서버를 띄우고 나서 보여줄 index.html를 작성하고 저장한다.
<!DOCTYPE html>
<html>
<head>
<title>AUSG Bigchat</title>
</head>
<body>
<h1>Auto Scaling Test!!</h1>
</body>
</html>
Auto Scaling을 통해 생성될 ec2 인스턴스에 s3 access 권한을 부여하기 위해 IAM도 생성해주었다.

- Policy : AmazonS3FullAccess
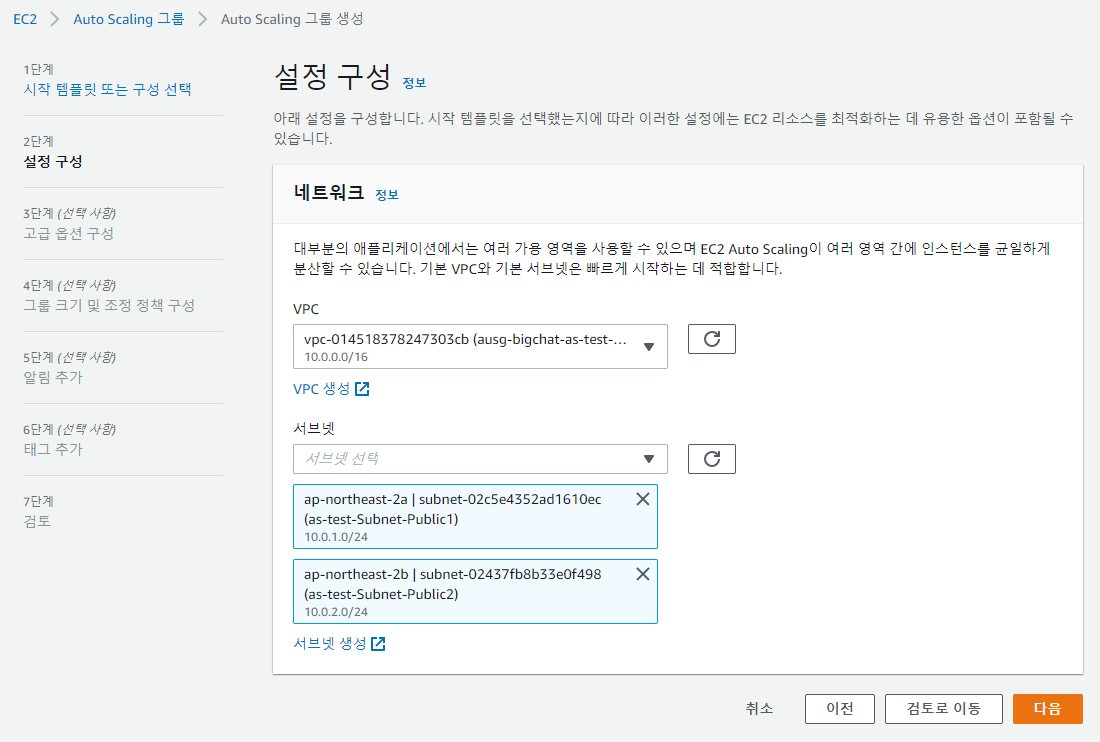
2. VPC 및 Subnet 구성
Auto Scaling을 테스트할 인프라 구성을 위해 VPC를 하나 생성한다.

Public Subnet도 2개 생성해주고

이전 포스팅에서 다뤘던 것처럼 Internet Gateway 생성 후 VPC와 연결해주자.

Route Table 생성 후 Public Subnet 2개와 연결해주고

인터넷 연결을 위해 0.0.0.0/0 (모든 네트워크)에 대해서 Routes를 추가해준다.

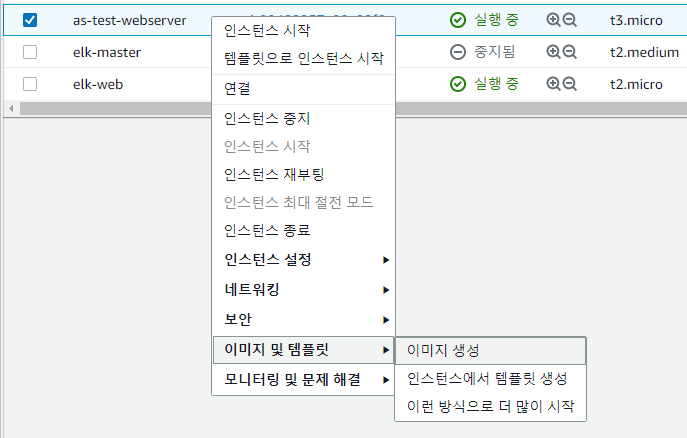
3. EC2 AMI 생성
Auto Scaling에 사용할 AMI를 생성할 차례이다.
우선 인스턴스를 하나 생성하자.

- AMI : Amazon Linux 2 AMI (HVM), SSD Volume Type
- Instance Type : t3.micro (2vCPU 1GiB)
- Network : 위에서 만든
ausg-bigchat-as-test-VPCVPC - Subnet : 위에서 만든
as-test-Subnet-Public1서브넷 - IAM Role : 위에서 만든
s3_fullaccess_as_testIAM - User Data
#!/bin/bash yum install -y httpd systemctl start httpd.service systemctl enable httpd.service aws s3 cp s3://ausg-bigchat-as-test/index.html /var/www/html –region ap-northeast-2
user data란 ec2 인스턴스가 올라가면서 수행할 action을 정해주는 것이다.
이번 시나리오에서는 간단하게 웹서버(httpd)를 설치하고 아까 만든 S3버킷에서 index.html을 받아올 것이다.
생성된 인스턴스를 기준으로 AMI를 생성한다.

4. Elastic Load Balancer 구축

- Type : Application (L7)
- 체계 : internet-facing
- IP 주소 유형 : ipv4
- VPC 및 Subnet : 위에서 만든 것
TargetGroup을 생성하고 대상으로 생성해놓은 ec2 web서버를 지정한다.


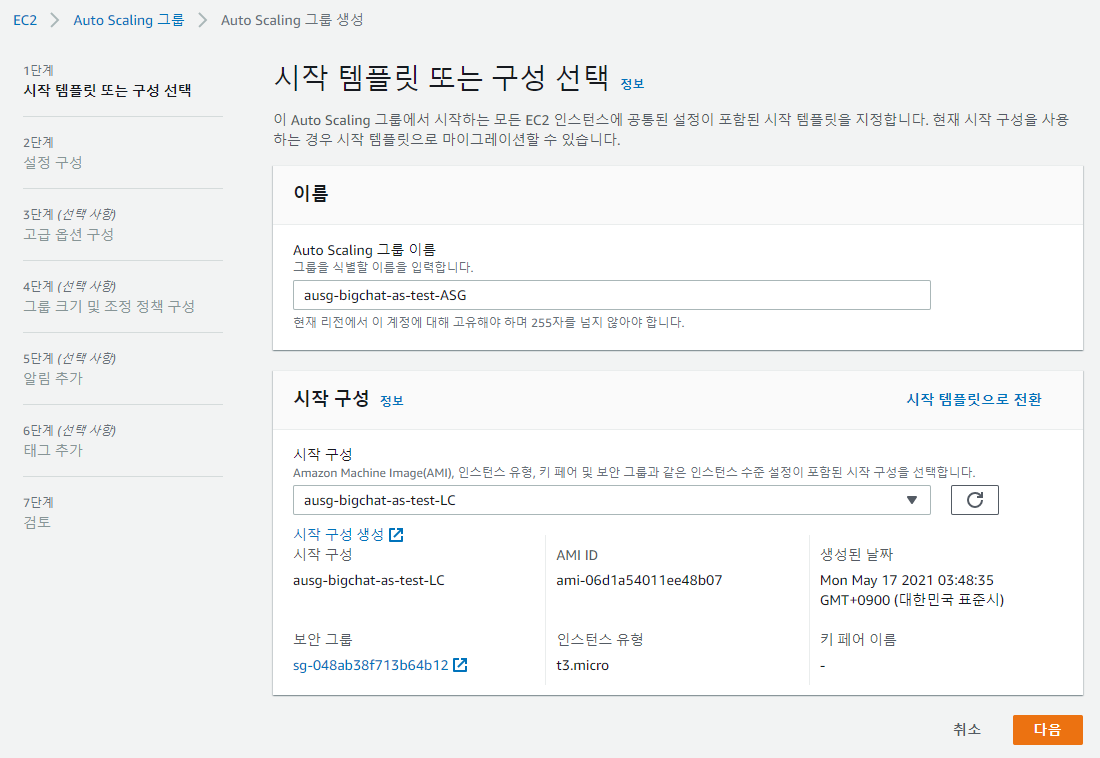
4. Autoscaling Launch Configuration 생성
Auto Scaling Launch Configuration(시작 구성) 생성

- Amazon Machine Image(AMI) : web서버 인스턴스로부터 만든 이미지
- Instance Type : t3.micro (2 vCPU, 1 GiB, EBS 전용)
- IAM : s3_fullaccess_as_test
- Security Group : 동일하게
- Key pair : 동일하게
- user data
#!/bin/bash yum install -y httpd systemctl start httpd.service systemctl enable httpd.service aws s3 cp s3://ausg-bigchat-as-test/index.html /var/www/html –region ap-northeast-2
5. Auto Scaling Group 생성
1) Launch Configuration 선택
위에서 만들었듯이 Launch Configuration은 오토스케일링 그룹에서 생성될 서버의 사양과 설정을 정의하는 것이다.
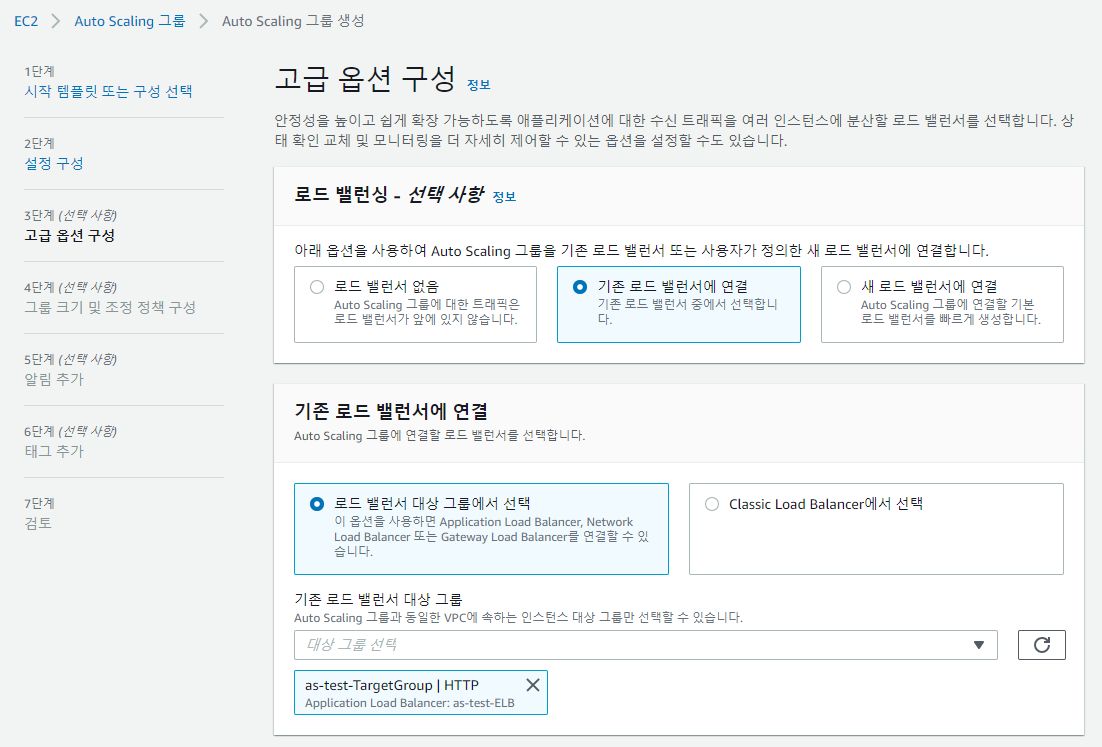
3. ELB 연결
Elastic Load Balancing(ELB) 상태 확인을 활성화하면 연결된 로드 밸런서가 Amazon EC2 상태 확인에 실패할 때뿐만 아니라 비정상으로 보고할 때 Amazon EC2 Auto Scaling에서 인스턴스를 교체할 수 있다.
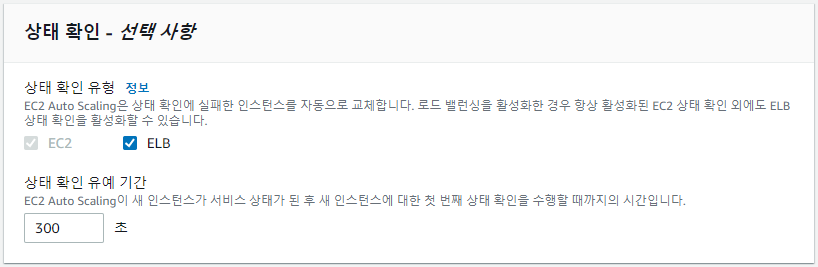
상태확인 유예 기간은 300초가 적당하다.
우후죽순으로 빨리빨리 만들어져봐야 소용없기 때문.
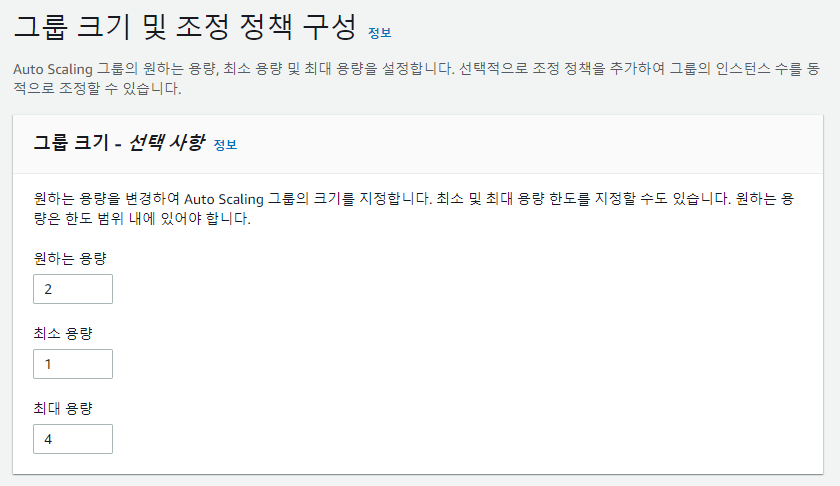
4) Auto Scaling Group Size
- Desired Size : 오토스케일링 시 원하는 서버 수를 지정
- Min Size : 오토스케일링 그룹의 최소 유지 서버 수 (Desired > = MinSize)
- Max Size : 오토스케일링 그룹의 최대 보유 서버 수 (Desired < = MaxSize)
5) scaling policies
오토스케일링 그룹에 포함된 가상 서버의 시스템 메트릭 값이 미리 지정한 임계치를 초과할 경우 가상서버 수를 늘리고(Scale-out), 임계치 미만이면 가성 서버 수를 줄이도록(Scale-in) 설정할 수 있다.
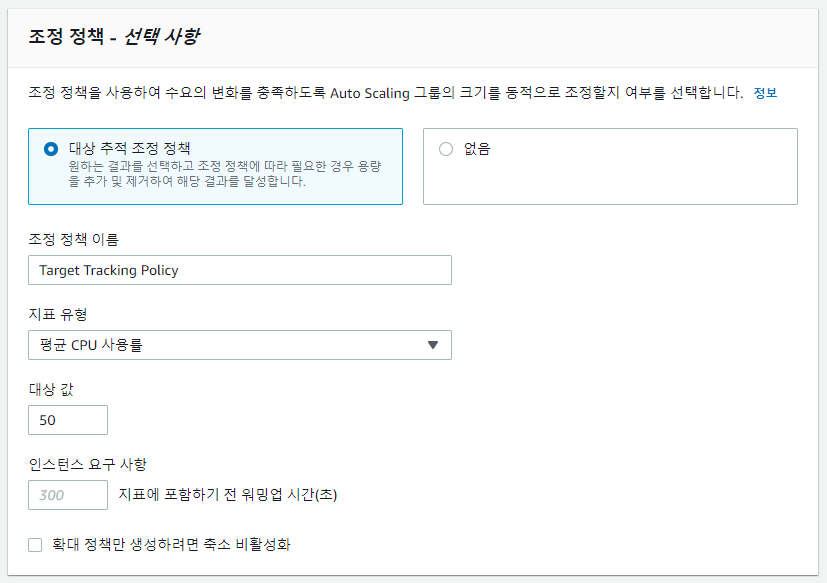
지표 유형에는 아래와 같은 것들이 있다.
- 평균 CPU 사용률
- 평균 네트워크 입력 (bytes)
- 평균 네트워크 출력 (bytes)
- 대상당 Application Load Balancer 요청 수
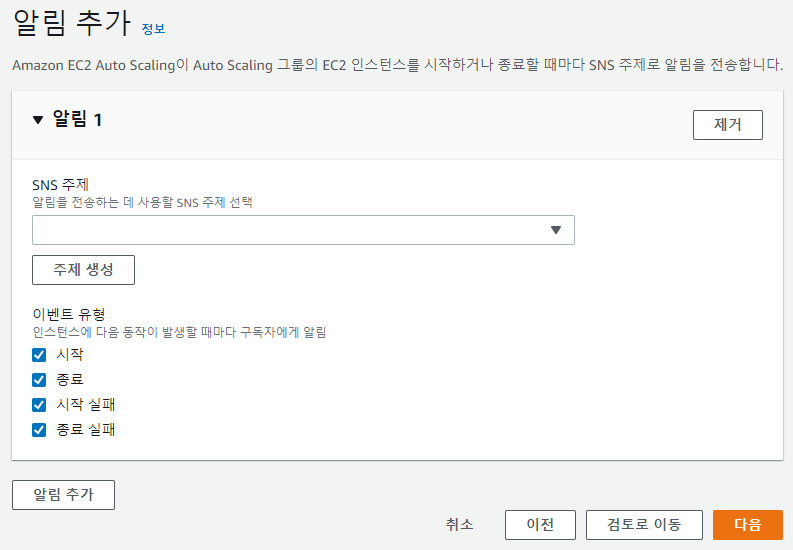
6) 알림 추가
6. Autoscaling Group 생성 후 인스턴스 확인
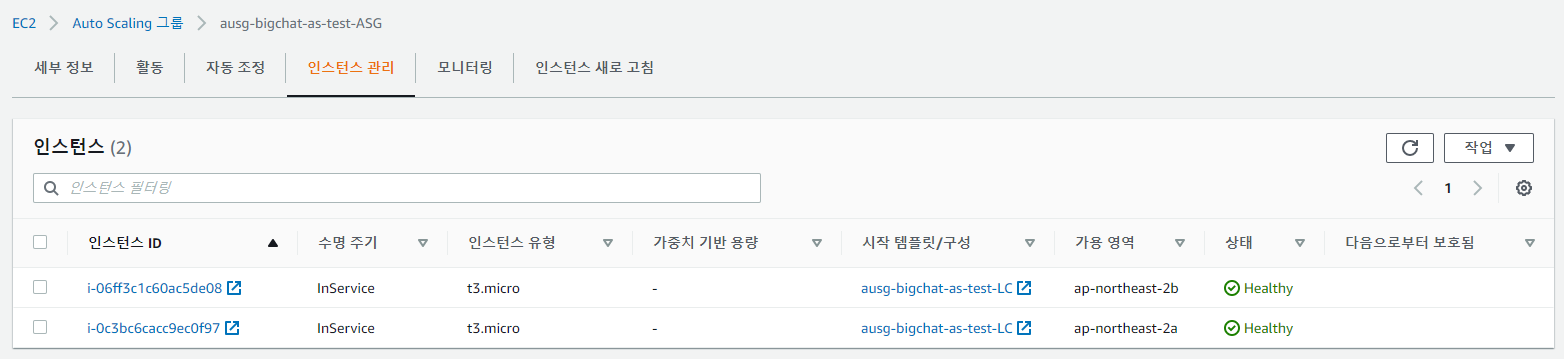

Desired Size를 2로 지정하였기 때문에 2대의 ec2 인스턴스가 올라온 것을 확인할 수 있다.
7. ELB Target Group 확인
Scale-out 된 인스턴스들이 ELB에 자동으로 연결된 것을 확인할 수 있다.
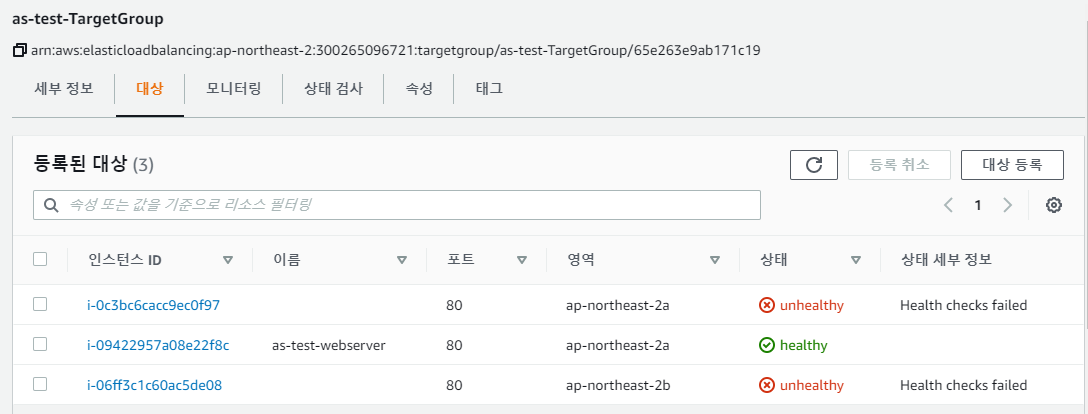
현재 Scale-out 된 인스턴스들에 웹서버 설치가 되지 않아 unhealthy 상태로 체크된다.
아까 Auto Scaling Group 생성 시 Health Check Type에 ELB를 체크하였기 때문에 unhealthy 상태의 인스턴스를 삭제하고 새로 생성하는 작업을 반복한다.
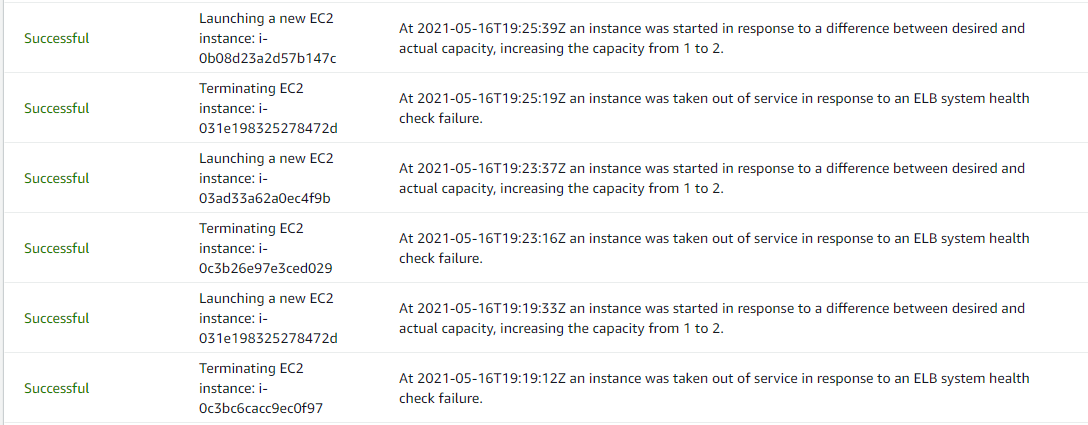
인프라 구성을 맞추기 위해 기존에 등록한 AMI용 인스턴스는 언바인딩 하였으며, ELB DNS 접속도 정상적으로 되는 것을 확인하였다.

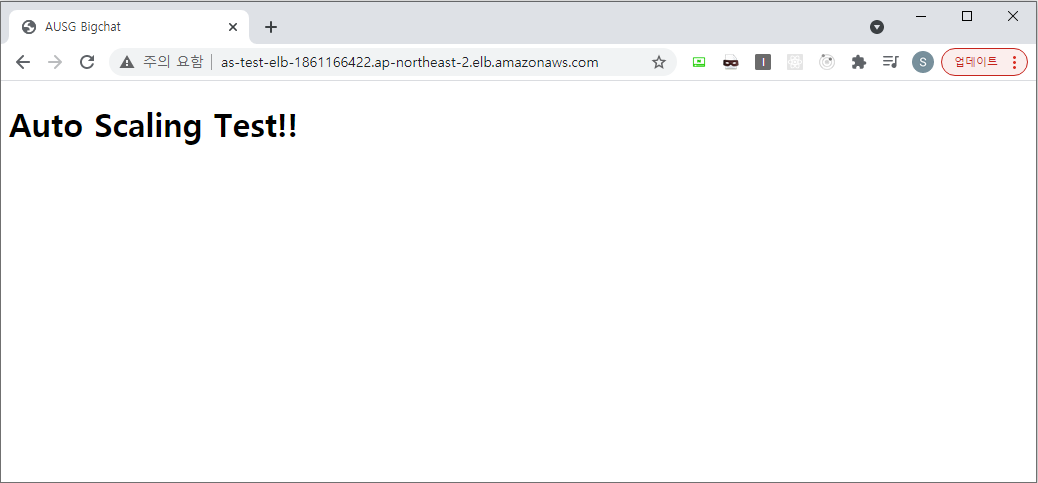
8. CloudWatch 경보 및 조정정책 설정
우선 단계 조정정책 또는 단순 조정정책을 생성하기 위해 CloudWatch 경보를 생성해야 한다.
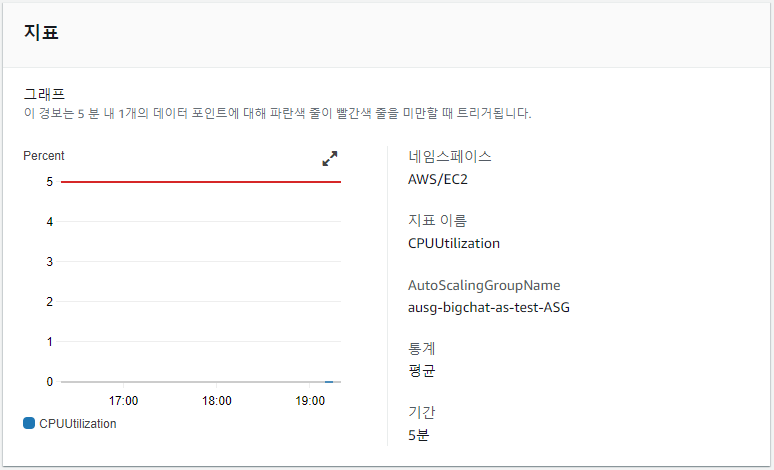
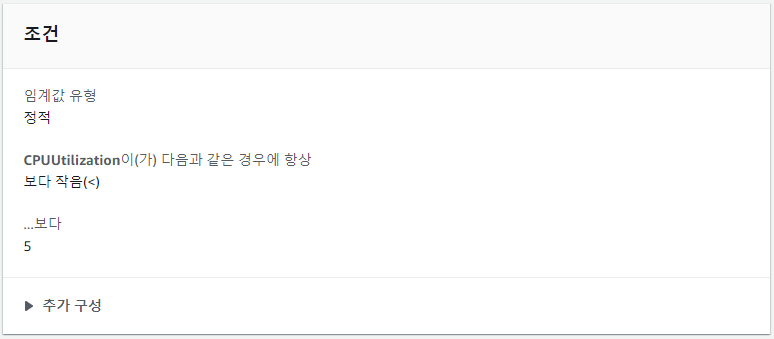
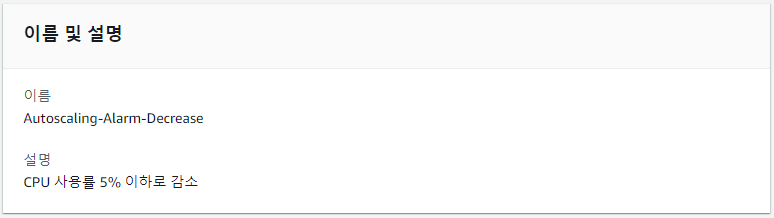
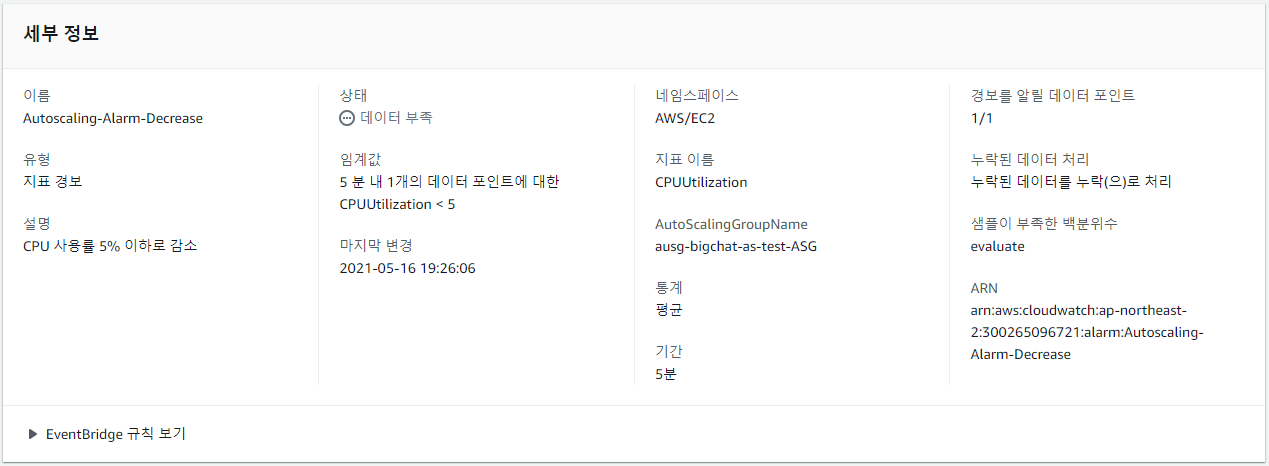
Auto Scaling Group의 CPU 사용률이 5% 이하면 경보가 발생하도록 설정하였다.
자고 일어났다...
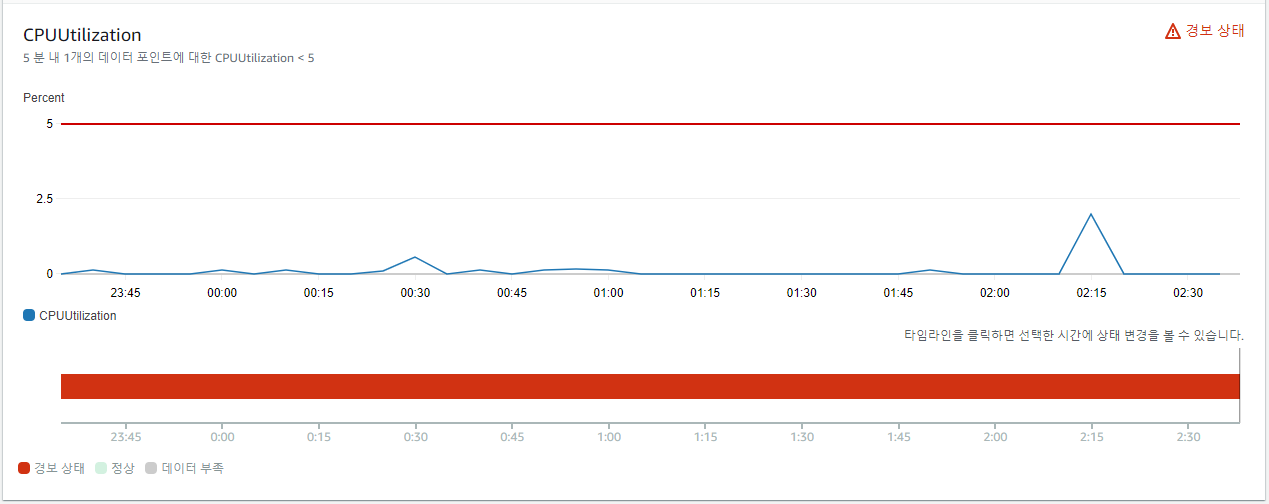
당연히 아무것도 하지 않기 때문에 CPU는 5% 이하가 유지되고 있었으며, 경보가 발생한 상태이다.

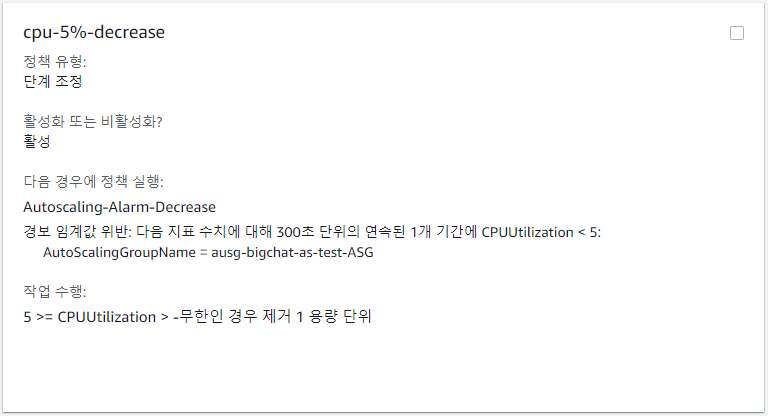
해당 경보를 이용하여 경보가 발생하면 인스턴스가 1개 Scale-In 되도록 단계 조정정책을 추가하였다.
인스턴스 하나가 내려가는 것을 확인할 수 있다.


Scale-out 도중 ELB 언바인딩 또한 진행된다는 것을 알 수 있다.


또한 예약 작업을 생성하여 원하는 시간대에 Auto Scaling Group 사이즈를 유연하게 조정할 수 있으며, 인스턴스 개수 또한 조정 가능하다.
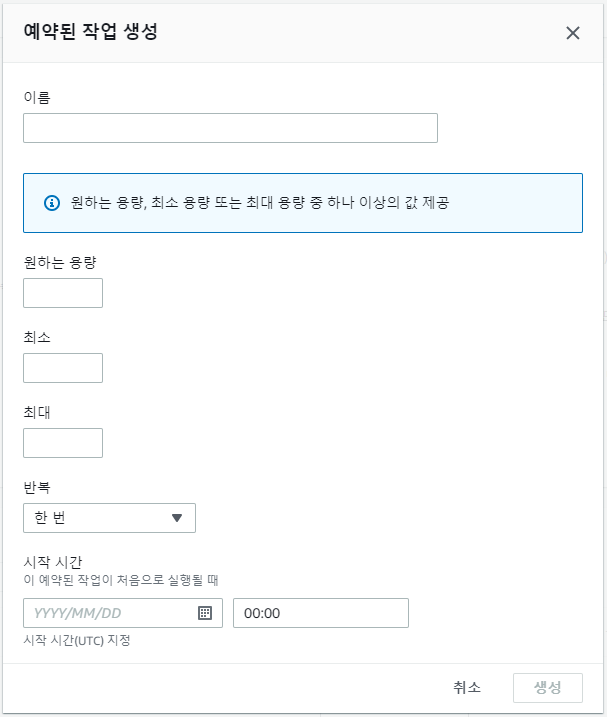
9. cpu 부하 테스트 (Scale-out)
Scale-out 테스트를 위해 CloudWatch에서 CPU 사용률이 60% 이상이 되면 발생하는 경보를 추가하였다.
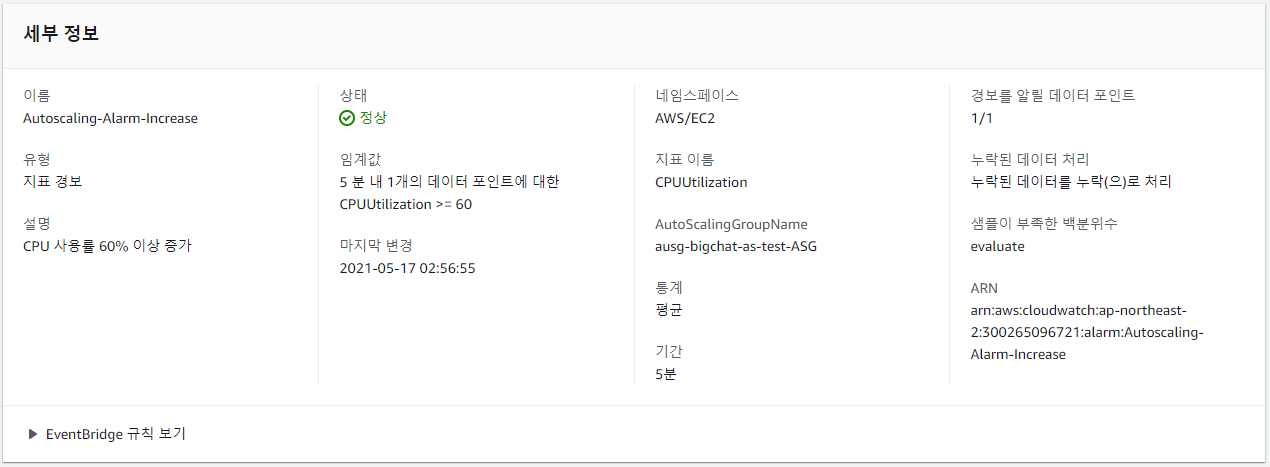

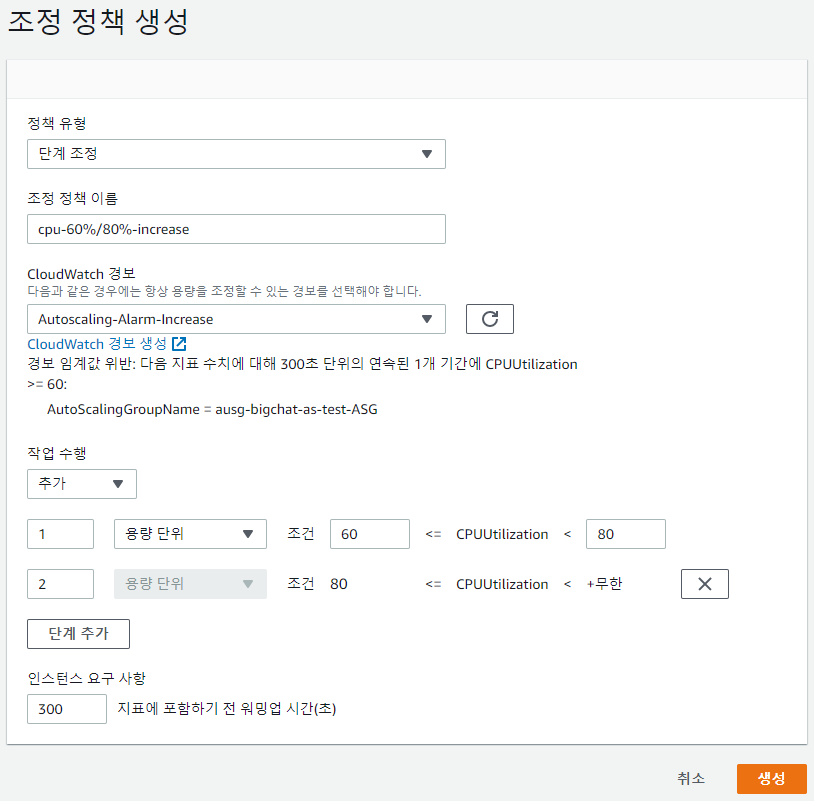
해당 경보를 이용하여 조정 정책을 생성한다.
CPU 사용률이 60%~80%이면 1개의 인스턴스를 증가시키고, 80% 이상이면 2개의 인스턴스를 증가시킨다.
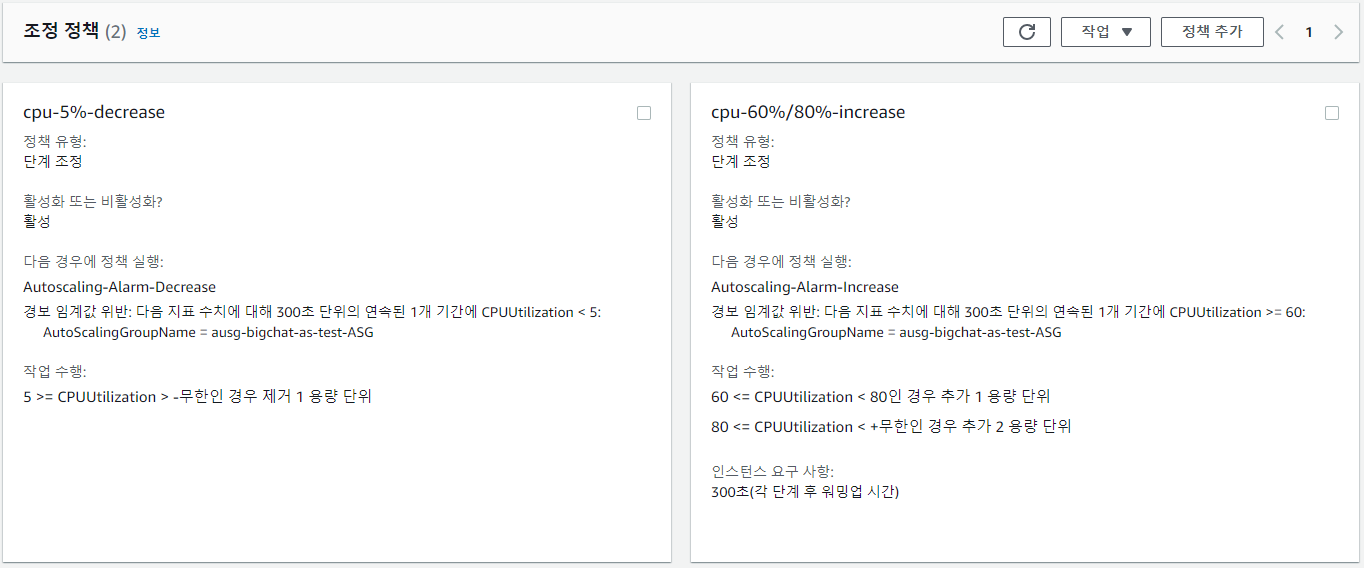
현재 Auto Scaling Group에는 아래와 같이 2개의 조정정책이 설정되어 있다.
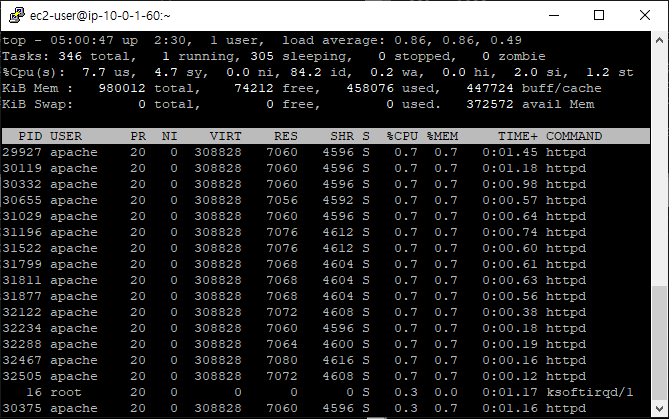
부하 발생을 위해 Auto Scaling Group 내의 인스턴스에서 stress를 주었다.
$ sudo amazon-linux-extras install epel
$ sudo yum -y install epel-release
$ sudo yum -y install stress
$ stress -c 2
top 명령어로 확인해보면 CPU 사용률이 100%까지 올라간 것을 확인할 수 있다.
CloudWatch에서 5% 이하 경보는 해제되고 60% 이상 경보가 발생한다.

80%를 넘어 100% 사용률을 나타내고 있다.
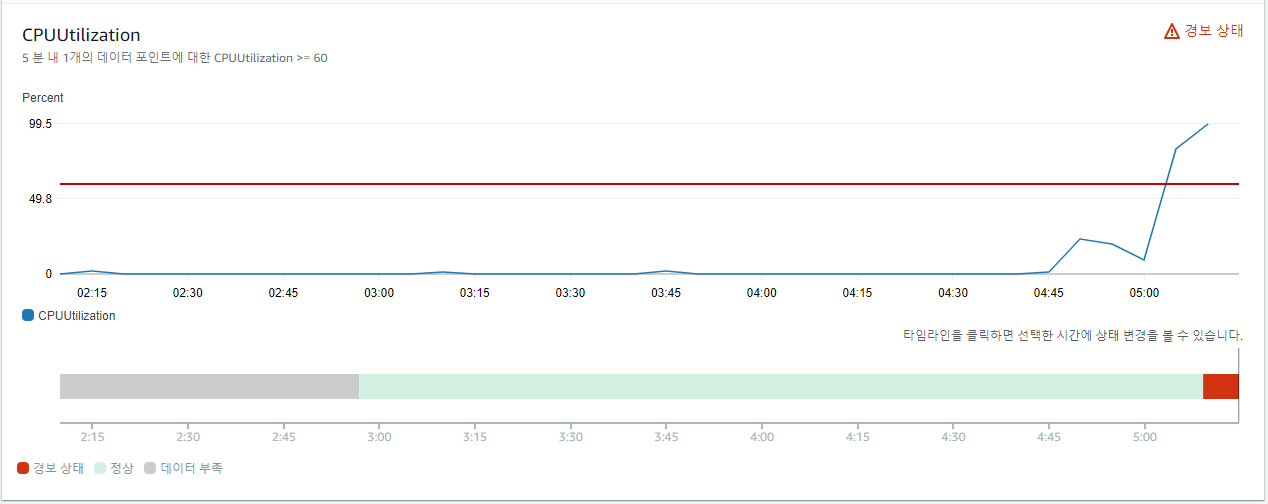
cpu 사용률이 80% 이상이면 인스턴스 2개가 증가하도록 조정정책을 설정해 놓았기 때문에, 2개의 인스턴스가 Scale out 되는 것을 확인할 수 있다.


지정해놓은 300초(5분)가 지나자 아직 경보가 해제되지 않았기 때문에 인스턴스가 1대 더 Scale out 되는 것을 확인할 수 있다.
또한 Auto Scaling Group 내에서 AZ 또한 유연하게 분산배치된 것을 확인할 수 있다.


Auto Scaling Group에 총 4대의 인스턴스가 올라가 Cpu 평균 사용률이 감소하고 경보가 해제되는 과정 또한 확인할 수 있다.
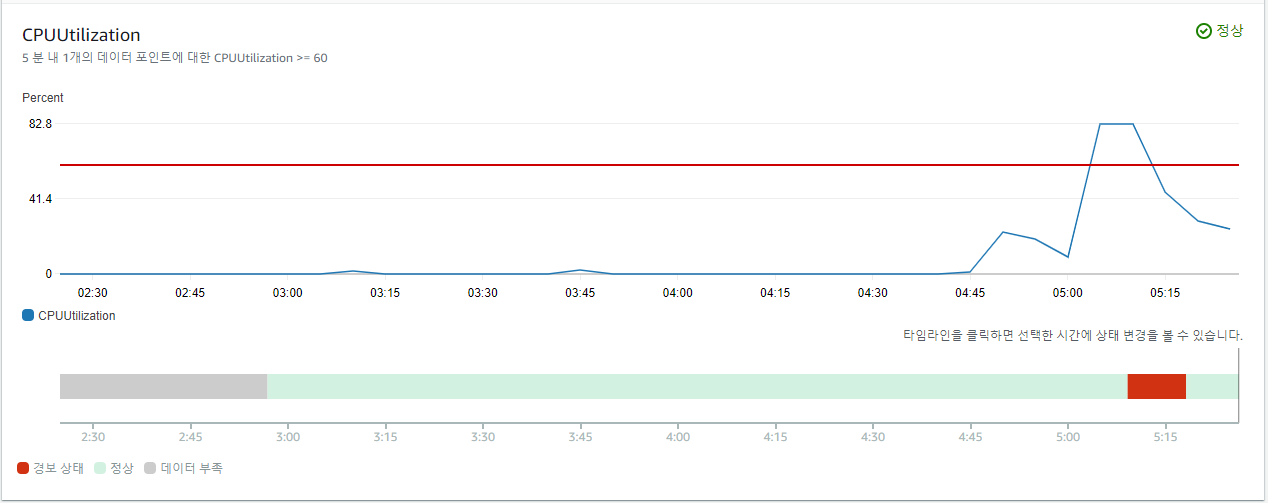
이것이 Auto Scaling을 사용하는 이유이다.