![[디지털이미지] JPEG 압축 이해하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F9T32C%2FbtqG3kSm8sA%2FAAAAAAAAAAAAAAAAAAAAAHlDazaI6INLLZ6UXQj_bznXs5ifqZJ6CNJ2kU9nkrAy%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DFO%252BRqa9O1%252BBrV8BlVEXSzJ1%252Bqxs%253D)
JPEG (Joint Picture Expert Group)
JPEG은 비트맵 방식의 이미지 압축 표준 중 하나이다.
손실 압축 기법을 사용하는 압축 알고리즘이며, 손실의 정도를 압축 매개변수들을 이용하여 조정할 수 있다.
당연히 손실이 심할수록 이미지 품질은 떨어지지만 압축률은 높아진다.
파일 크기가 작기 때문에 GIF, PNG와 함께 웹에서 가장 많이 사용되는 이미지 파일 형식이다.
JPEG 압축 알고리즘
1. 이미지 준비 (Sampling & Quantization)
아날로그 이미지에 표본화와 양자화를 수행하여 디지털 이미지로 변환한다.
이미지에서 표본화란 2차원 이미지의 x축과 y축을 일정한 표본으로 나누는 것이다.
우리가 흔히 말하는 해상도란 표본화의 결과이다.
인쇄 출력용 단위로는 DPI(Dots per Inch)를 사용하며, 모니터 출력용 단위로는 PPI(Pixel per Inch)를 사용한다.

이렇게 나뉘어진 각각의 pixel은 색 정보를 가지고 있다.
색은 빛의 파장으로 이루어져 있으며 자세한 내용은 이전 글을 참고하기 바란다.
아무튼 연속된 빛의 파장을 이산 값으로 변환하기 위해 양자화를 수행해야 한다.
이미지의 경우 보통 1bit, 8bit, 24bit로 양자화한다.
◾ 1bit : 흑백(BW)
◾ 8bit : Gray Scale
◾ 24bit : True Color
True Color란 사람이 볼 수 있는 색이라는 뜻이며 R, G, B 각각의 신호에 8bit를 할당하여 총 16,777,216(2^24) 가지의 색상을 표현할 수 있다.
색상을 표현하는데 24bit까지 할당할 필요가 없다고 생각하여 확률적으로 가장 많이 사용되는 256개의 RGB 조합을 선정하여 구성한 8bit Color Map 규격이 사용되기도 한다.
2. 색 공간 변환 (RGB → YCbCr)
디지털 이미지가 준비됐다면, RGB로 양자화된 색 공간을 YCbCr 색 공간으로 변환한다.
YCbCr 방식에서 Y는 밝기 정보를 표현하며, Cb·Cr는 색상 정보를 표현한다.
색 공간을 YCbCr 방식으로 변환하는 이유는 1차적인 압축을 하기 위해서이다.
사람의 눈은 색상보다 밝기에 훨씬 민감하다.
따라서 밝기 정보를 가지는 Y 성분은 유지하고, 색상 정보를 가지는 Cb·Cr 성분을 줄여서 압축을 하는 것이다.
이를 다운샘플링(downsampling) 또는 크로마 서브샘플링(chroma subsampling)이라고 한다.
다운샘플링 규칙은 아래와 같다.
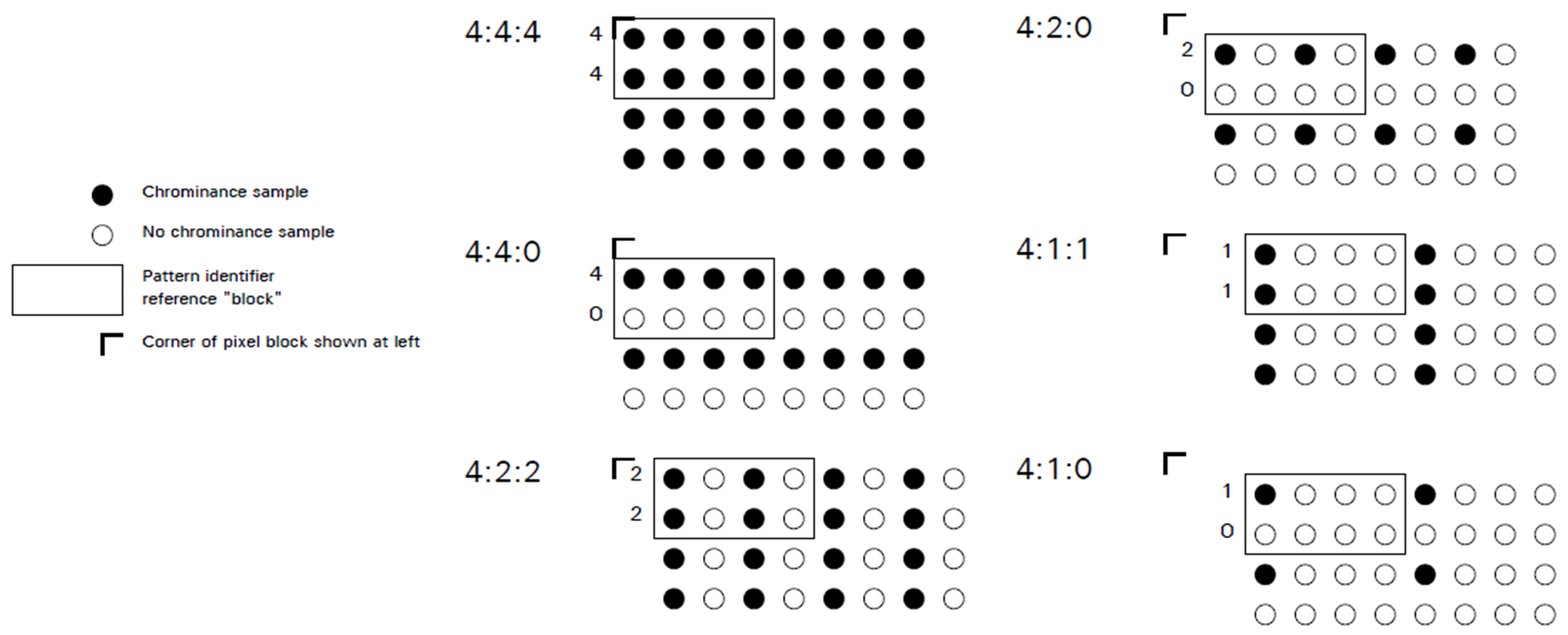
인접한 픽셀들끼리 그룹을 정한 후 어느 픽셀 값을 버릴지 선정하고, 남은 픽셀이 해당 그룹을 대표하는 값이 된다.
Y 성분은 다운샘플링 하지 않으며, Cb·Cr 성분에 대해 다운샘플링을 수행한다.
아래 예시를 보면 이해가 조금 더 쉬울 것이다.

일반적으로 JPEG 이미지에서는 4:4:4, 4:2:2, 4:2:0 비율로 다운샘플링을 수행하며 주로 4:2:0 방식이 사용된다.
3. Block splitting (8x8)
다운샘플링 후 각각의 채널을 8x8 크기의 블록으로 분할한다.
엄밀히 말하자면 Y채널은 8x8 블럭으로, CbCr채널은 다운샘플링 방식에 따라 각각 8x8(4:4:4), 16x8(4:2:2), 16x16(4:2:0)으로 분할한다.
이를 Macro Block이라고 한다.
채널 분리가 없다고 가정하고 정말 간단하게 생각하자면, 640*400 해상도 이미지의 경우 4000개의 Macro Block이 생성되는 것이다. (가로 80, 세로 50)
4. DCT (Discrete Cosine Transform) - 이산 코사인 변환
이미지에서 인접한 픽셀과의 차이가 작은 경우 낮은 공간주파수 (저주파)를 가진다.
반대로 인접한 픽셀과의 차이가 큰 경우 높은 공간주파수 (고주파)가 나타난다.

위 그림에서 상단의 이미지가 하단의 이미지보다 인접한 픽셀과의 색상 차이가 작다.
이미지의 주파수를 비교해보면, 확실히 하단의 이미지가 고주파 주파수로 표현되는 것을 볼 수 있다.
사람의 눈은 작은 변화보다 큰 변화에 민감하다.
저주파 성분이 손실되면 인접한 픽셀과의 차이가 작았기 때문에 "큰 변화"로 인식된다.
반면, 고주파 성분은 손실되더라도 원래 인접한 픽셀과의 차이가 컸기 때문에 "작은 변화"로 인식하게 된다.
따라서 저주파 성분은 유지하고 고주파 성분을 줄이는 방식으로 압축을 진행한다.
저주파 성분과 고주파 성분을 분리하기 위해 이미지를 공간 영역에서 주파수 영역으로 변환해야 한다.
이를 직교변환이라 하는데 그중 가장 많이 사용되는 방법이 DCT 방법이다.

각각의 8x8 블럭에 DCT 변환을 수행하면 공간 영역(Spatial Domain)에서 주파수 영역(Frequency Domain)으로 변하며 좌측 상단에 저주파 성분이 배치되고, 우측 하단에 고주파 성분이 배치된다.

DCT 변환식은 아래와 같다.


각 블럭의 64개 값이 DCT 변환식을 거치면 64개의 DCT 계수를 얻게 된다.
DCT 계수 중 가장 처음 얻는 값인 0차 계수(0,0)는 다른 계수들과 달리 코사인의 함수가 아니다.
이를 DC 계수라고 하며 나머지 63개의 값은 AC 계수라고 한다.
(0,0)에 위치하는 DC 계수는 해당 블록 전체의 명도를 결정하는 평균 색상 값을 가진다.
대부분의 이미지의 경우 인접한 픽셀은 거의 비슷한 색상으로 형성되어 있기 때문에 DC 성분에 값이 집중된다.
따라서 평균값과 비슷한 성분(저주파)이 DC 근처인 좌측 상단에 몰리게 되며, 평균값과 차이가 많이 나는 성분(고주파)은 DC와 멀어지게 되는 것이다.
아래는 하나의 블록에 대해 DCT를 수행한 결과이다.

5. 양자화 수행 (Quantization)
양자화는 고주파 성분을 제거하기 위한 방법이다.
주파수 영역의 각 계수에 대해 양자화 행렬의 상수로 나눈 후 반올림한다.
일반적으로 사용되는 양자화 행렬은 다음과 같다.

전체적으로 저주파 성분이 모여있는 좌측 상단은 작은 값으로 나누며, 고주파 성분이 위치한 부분은 큰 값으로 나누는 것을 알 수 있다.
압축률을 높이고 싶다면 양자화 테이블의 값을 더욱 크게 하면 되고, 압축률을 줄이는 대신 이미지 품질을 높이고 싶다면 양자화 테이블의 값을 줄이면 된다.
위에서 구한 DCT 계수 블록에 양자화를 수행해보자.

일반적으로 많은 고주파 성분이 0으로 반올림되었음을 볼 수 있다.
대부분의 나머지 성분 또한 작은 양수 또는 음수가 되어 표현하는데 이전보다 훨씬 적은 비트가 사용된다.
6. Entropy Coding
엔트로피 코딩은 무손실 압축 기법이며 자세한 내용은 이전 글을 참고하기 바란다.
모든 블록이 양자화 과정까지 마쳤다면 이 양자화된 DCT 계수들을 압축하기 위한 단계가 남아있다.
이때 DC 계수와 AC 계수의 압축 방법이 다르다.
우선 DC 계수의 경우 이전 블록의 DC 계수와 현 블록의 DC 계수 간의 차분으로 부호화한다.
이게 무슨 소리냐면...
위에서 일반적인 이미지에서 인접한 픽셀은 거의 비슷한 색상으로 구성되어 있다고 하였다. (DCT 부분)
인접한 블록의 DC 계수 또한 비슷할 것이며, 이전 블록의 DC 계수로부터 현재 블록의 DC 계수를 예측할 수 있다.
따라서 기준 표본 값과 예측값의 차이 값을 저장하는 방식의 압축 알고리즘인 DPCM(Different PCM)이 사용되는 것이다.
DPCM에 자세한 내용은 이전 글을 참고하기 바란다.
AC 계수의 경우 블록 내의 63개의 값으로만 부호화한다.
이때 zigzag scanning 기법이 사용된다.

지그재그 스캐닝이란 위 그림과 같이 8x8 형태의 행렬을 지그재그 형태로 읽어 일차원 배열로 나열하는 것이다.
우리가 예시로 사용한 양자화된 DCT 계수들에 이 방법을 적용해보자.

지그재그 형태로 읽었기 때문에 유사한 값이 연속으로 나타나게 된다.
이렇게 나열된 63개의 AC 계수 값들에 런렝스 부호화(Run-length Encoding)를 적용한다.
JPEG 압축 시 사용되는 런렝스 부호화는 0(zero)을 기준으로 아래와 같은 형태로 부호화된다.
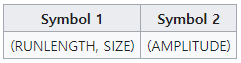
Symbol1의 RUNLENGTH는 앞에 0(zero)이 몇 개 있는지를 뜻한다.
즉 63개의 AC 계수 스트림 이 런렝스 부호화를 거치면, 아래와 같이 부호화된다.

(0,0)은 EOB(end of block)을 뜻한다.
일반적으로 AC 계수 스트림에서 '0'이 뒤에 나열되기 때문에 런렝스 부호화 후 데이터 크기가 대폭 압축되는 것이다.
참고로 DC 계수는 (SIZE, AMPLITUDE) 형태로 부호화된다.
만약 이전 블록의 DC 계수가 +12였다면 (2,3)으로 저장되는 것이다.
최종적으로 우리가 다뤄왔던 8x8 블록은 (2,3) (1,2)(-2) (0,1)(-1) (0,1)(-1) (0,1)(0,1) (2,1)(-1) (0,0)으로 부호화된다.
마지막으로 이 데이터에 허프만 부호화(Huffman Coding)를 적용하면 JPEG 압축은 끝이 난다.